Gần đây hệ thống tôi đang phát triển liên tục gặp các sự cố liên quan tới I/O Bound và CPU Bound, CPU Server liên tục gặp tình trạng quá tải (100% high load), theo phản ứng bình thường thì các Developer sẽ đổ tại Server yếu sinh lý, không đủ tải hệ thống v.V... và yêu cầu nâng cấp hay mở rộng phần cứng ...blah blah và blah blah...
Nhưng tui thì lại nghĩ rằng liệu có thể cải tiến hệ thống để thân thiện, đồng điệu và hoạt động tốt hơn với phần cứng hay không? Và câu hỏi này đã đưa tui đến với khái niệm Mechanical Sympathy, khái niệm này do một ông Racer nói, đại loại là khi lái xe phải cảm nhận được xe, phải nghe từng hơi thở của xe... theo phong cách Kim Dung có thể gọi là "Nhân Xa Hợp Nhất" vậy =)))
Ở trong trường hợp này ta cũng có thể diễn dịch ra là "lập trình phần mềm đồng điệu với phần cứng" (hardware and software working together in harmony).
Vậy vì sao chúng ta phải quan tâm với mechanical sympathy? Code liên quan tới phần mềm sao tui phải quan tâm tới phần cứng làm chi cho mệt ? Bởi vì có 3 lý do chính sau đây:
- Hiểu biết rõ về phần cứng cơ bản sẽ giúp bạn trở thành một developer tốt hơn, đặc biệt hơn và độc hơn .... tất nhiên rồi :P.
- Chia sẻ bộ nhớ (share memory) giữa các thread rất dễ gặp lỗi, chúng ta phải rất cẩn thận khi sử dụng.
- Sử dụng bộ nhớ của CPU (CPU cache) nhanh hơn sử dụng bộ nhớ đệm chính (DRAM), nhưng nếu sử dụng mà không hiểu rõ cách hoạt động (ví dụ như khái niệm cache lines v.V...) sẽ làm mọi thứ trở nên tồi tệ hơn.

Ảo tưởng về bộ nhớ chung (Shared Memory)
Các process/thread của CPU sẽ sử dụng chung một vùng không gian nhớ chung (share memory). Việc tương tác giữa hai process sẽ hoàn toàn do việc đọc/ghi trên vùng nhớ chung này. OS không hề can thiệp vào quá trình này, thế nên shared memory là phương pháp nhanh nhất (nhanh về mặt tốc độ) để các process nói chuyện với nhau. Tuy nhiên, nhược điểm của phương pháp này là các process phải tự quản lý việc đọc ghi dữ liệu, và quản lý việc tranh chấp tài nguyên (race condition).
Hãy bắt đầu về một ví dụ đơn giản là chúng ta cần tăng dần 1 biến đếm từ giá trị 0 đến MAX bằng vòng lặp tuần tự sau đây:
Vấn đề là giá trị MAX có thể rất lớn, vậy làm thế nào để tăng tốc độ counter lên? Và theo tư duy thông thường thì ta sẽ nghĩ đến việc xử lý multi-thread tức là sử dụng nhiều hơn 1 thread để tính toán, ví dụ sau đây ta sử dụng 2 thread để xử lý việc tăng dần biến counter với hy vọng rằng tốc độ thực thi sẽ giảm một nửa ???
Nhưng chúng ta sẽ có vấn đề sau khi sử dụng nhiều hơn 1 thread đó là:
1. Race Condition
Hãy thử chạy lại nhiều lần đoạn code bên trên với giá trị MAX là 1 triệu, chúng ta sẽ kỳ vọng rằng biến sharedCounter sẽ có giá trị là 1.000.000 phải không ???
Nhưng thực tế thì mỗi lần chạy kết quả sẽ ra khác nhau và tất nhiên là sẽ chẳng bao giờ bằng giá trị chúng ta kỳ vọng, với 3 lần chạy thử chúng ta sẽ có kế quả như sau:
counter=558901
counter=621211
counter=527666Chắc bạn đọc biết thừa từ khi đọc đoạn code bên trên của tui rằng... race condition chắc chắn sẽ xẩy ra, bởi ở đây sharedCounter đang được hai thread t1 và t2 cùng truy cập và sửa đổi đồng thời và kết quả sẽ phụ thuộc vào tốc độ thực thi của từng thread.
2. CPU caches
Nếu ta tạm thời việc bỏ qua race condition thì nếu MAX được gán thành một giá trị đủ lớn để làm cho việc chạy multi-thread ở đây là 2 thread cũng sẽ chẳng có khác biệt gì cả, thì thực tế là việc thực thi vẫn chậm hơn 3 lần so với chạy 1 thread. Ngạc nhiên chưa ??? Và lý do là gì ???
Với các thế hệ CPU hiện tại bây giờ thì kiến trúc CPU sẽ có nhiều lõi (CPU core), và khi chúng ta sử dụng multi-thread thì hệ điều hành (OS) sẽ phân chia mỗi thread vào từng CPU core. Và chúng ta nghĩ rằng việc mỗi thread chạy trên từng CPU core vẫn có thể dùng chung bộ nhớ (shared memory), như trường hợp trên là có thể cùng truy cập và sửa đổi biến sharedCounter?. Thực tế là hầu hết chúng ta đã quên mất khái niệm CPU caches.
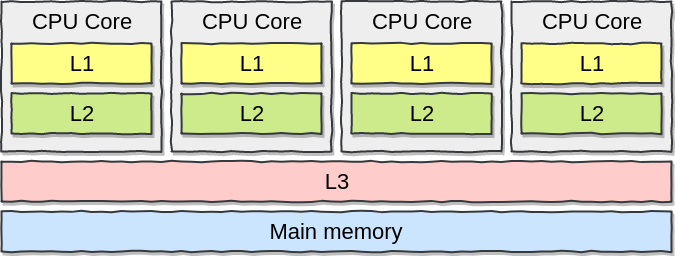
Mỗi CPU core đều có bộ nhớ cache riêng đó là bộ nhớ L1, L2 và bộ nhớ chung (share memory) L3 cho tất cả các lõi (CPU core) và CPU sẽ cache data lên đó. Vì vậy thay vì chương tình sẽ truy vấn và DRAM thì chương trình sẽ truy vấn vào bộ nhớ riêng L1, L2 trước nếu không thấy thông tin hợp lệ thì mới truy cập vào share memory L3 hoặc main memory (DRAM).
Chú ý rằng bộ nhớ của L1 và L2 khá nhỏ 32kb với L1 và 256kb với L2.
Quote lại từ WIKI với khái niệm CPU Caches
CPU cache là bộ nhớ được dùng bởi bộ xử lý trung tâm của máy tính nhằm giảm thời gian truy cập dữ liệu trung bình từ bộ nhớ chính (DRAM). Cache là một bộ nhớ nhỏ hơn, nhanh hơn và lưu trữ bản sao của những dữ liệu thường xuyên được truy cập trên bộ nhớ chính. Hầu hết CPU đều có các bộ nhớ cache độc lập khác nhau, bao gồm cache chỉ dẫn và cache dữ liệu, nơi mà dữ liệu được xếp thành nhiều lớp khác nhau.
Khi mà bộ xử lý cần phải đọc hay viết vào một vị trí trong bộ nhớ chính, nó sẽ tìm trong bộ nhớ cache đầu tiên. Nhờ vậy, bộ xử lý đọc hay viết dữ liệu vào cache ngay lập tức nên sẽ nhanh hơn nhiều so với đọc hay viết vào bộ nhớ chính.
Để dễ cho việc so sánh tốc độ thực thi khi CPU truy cập vào bộ nhớ riêng L1, L2(internal caches) hay bộ nhớ chung L3 (shared cache) ta hãy xem bảng so sánh khi chạy thử với CPU Core i7 Xeon 5500
Khi chương trình muốn truy cập vào bộ nhớ đầu tiên sẽ tìm trên internal caches L1 nếu không có thì cache miss sẽ xảy ra và chương trình sẽ tiếp tục tìm kiếm trên internal cache L2 và tiếp tục tìm kiếm ở share cache L3 và cuối cùng là tìm ở bộ nhớ chính DRAM, và so với việc lấy được dữ liệu từ L1 thì việc lấy dữ liệu ở DRAM sẽ lâu hơn gần 60 lần (60 nano second so với 1,2 nano second).
Ở ví dụ trên khi biến sharedCounter được cùng truy cập từ 2 thread từ 2 CPU core vào cùng 1 thời điểm vì việc cùng 1 lúc phải update dữ liệu lên hai internal cache L1 lên hai CPU core sẽ giảm hiệu xuất chương trình một cách đáng kể.
3. Cache line
Một khái niệm nữa chúng ta cần phải hiểu về CPU cache là cache line, QUOTE lại từ WIKI khái niệm cache line
Dữ liệu được chuyển giữa bộ nhớ chính DRAM và CPU cache theo từng khối cố định kích cỡ, gọi là cache lines. Khi một cache line được sao chép từ bộ nhớ chính vào cache thì một cache entry được tạo ra. Nó sẽ bao gồm cả dữ liệu được sao chép và vị trí của dữ liệu yêu cầu (gọi là 1 tag).
Khi bộ xử lý cần đọc hoặc viết một vị trí trong bộ nhớ chính, nó sẽ tìm entry tương ứng trong cache đầu tiên. Cache sẽ kiểm tra nội dung của vị trí dữ liệu yêu cầu trong bất cứ cache line nào có thể có địa chỉ. Nếu bộ xử lý tìm thấy vị trí dữ liệu trong cache, một cache hit sẽ xảy ra. Tuy nhiên, nếu bộ xử lý không tìm thấy được vị trí dữ liệu trong cache, thì một cache miss sẽ xảy ra. Trong trường hợp cache hit, bộ xử lý đọc hoặc viết dữ liệu vào cache line ngay lập tức. Còn nếu là cache miss, cache sẽ tạo một entry mới và sao chép dữ liệu từ bộ nhớ chính, sau đó yêu cầu được đáp ứng từ nội dung của cache.
Cache line được quản lý với một bảng băm (hash-map) với mỗi địa chỉ lưu trong hash-map sẽ được chỉ định tới một cache line.
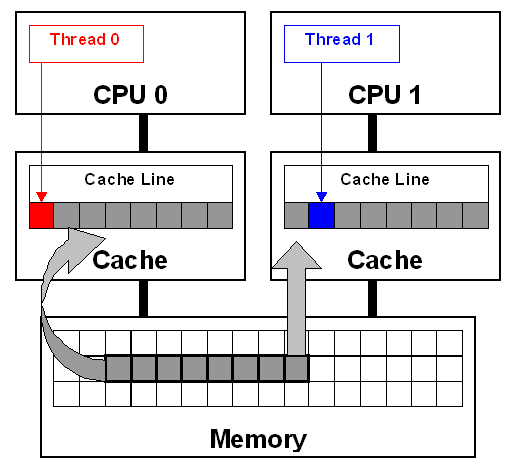
Có thể hiểu đơn giản là Cache Line là một bộ nhớ nhỏ làm trung gian giữa CPU Cache và Main Memory, giúp cho việc đọc hoặc ghi dữ liệu từ CPU Cache tới Main Memory.
Hãy lấy ví dụ ta có hai biến X và Y được truy cập với 2 thread từ 2 CPU core khác nhau, một thread thay đổi X và sau vài ns (nano second) thread còn lại thay đổi Y.
Nếu hai giá trị X, Y trên cùng một cache line (xác định bằng cách băm địa chỉ của X và Y và cả hai đều ra cùng 1 cache line) giả dụ là cache line của CPU core chứa thread 1, thì lúc đó thread 2 còn lại sẽ phải lấy một bản copy của Y từ cache line của thread 1 từ L2, L3 hoặc DRAM, trường hợp đó ta gọi là False Sharing, và chính điều này cũng ảnh hưởng đáng kể tới hiệu xuất của chương trình.
Tóm lại với hiểu biết CPU Cache và Cache Line thì việc chia nhỏ ứng dụng chạy với simple single thread khi đó mỗi thread sẽ chạy trên duy nhất 1 CPU core và nó sẽ chỉ truy cập vào local CPU cache (L1, L2) mà không truy cập ra ngoài share memory (L3, DRAM) sẽ cải thiện tốc độ chương trình và tiết kiệm tài nguyên của hệ thống lên rất nhiều lần.
Lập trình đa luồng - Concurrent programming
Để giải quyết những vấn đề về concurrent programming thì việc tuân thủ những main concepts của lập trình đa luồng để đảm bảo tính nhất quán của dữ liệu ta phải quan tâm tới 2 khái niệm sau:
1. Tương tranh - Mutual Exclusion (cơ chế loại trừ lẫn nhau)
Trong ngành khoa học máy tính, tương tranh là một tính chất của các hệ thống bao gồm các tính toán được thực thi trùng nhau về mặt thời gian, trong đó các tính toán chạy đồng thời có thể chia sẻ các tài nguyên dùng chung. Hoặc theo lời của Edsger Dijkstra: “Tương tranh xảy ra khi nhiều hơn một luồng thực thi có thể chạy đồng thời.” Việc cùng sử dụng các tài nguyên dùng chung, chẳng hạn bộ nhớ hay file dữ liệu trên đĩa cứng, là nguồn gốc của nhiều khó khăn. Các tranh đoạt điều khiển (race condition) liên quan đến các tài nguyên dùng chung có thể dẫn đến ứng xử không đoán trước được của hệ thống. Việc sử dụng cơ chế loại trừ lẫn nhau(mutual exclusion) có thể ngăn chặn các tình huống chạy đua, nhưng có thể dẫn đến các vấn đề như tình trạng bế tắc (deadlock) và đói tài nguyên (resource starvation).
Tóm lại Mutual Exclusion là ta phải đảm bảo trong một thời điểm chỉ duy nhất 1 thread được thực thi vào share memeory.
Vậy để thực hiện mục tiêu trên thì cơ chế Loking là cơ chế gần như bắt buộc phải thực hiện, thường ta có hai cơ chế locking thường được sử dụng là Pessimistic Locking và Optimistic Locking. Nhưng thực tế sử dụng lock sẽ gây lãng phí tài nguyên thread của CPU vì khi cơ chế locking được thực thi các thread khác sẽ bị block cho tới khi thread đang thực thi được giải phóng. Ngoài ra khi sử dụng lock không cẩn thận sẽ nảy sinh ra rất nhiều vấn đề như dead lock.
Thực tế thì làm thế nào và kiểu gì đi chăng nữa thì Concurrency Is Hard and Locks Are Bad, để minh hoạ cho việc này ta hãy chạy 3 kịch bản tăng biến counter ở đầu bài viết là chạy single thread, single thread có lock và Two threads có lock (Pessimistic Locking) với vòng loop là 500 triệu lần và kết quả sẽ như thống kê bên với.
Code viết lại với Single thread with lock:
Code viết lại với Two thread with lock:
Và kết quả khi chạy thử:
Kết quả có làm bạn ngạc nhiên không, với single thread tốc độ chạy nhanh hơn "Two thread with lock" là 1500 lần, quá khủng khiếp.
Ta cũng có thể giải quyết bài toán Mutual Exclusion bằng cơ chế CAS (compare-and-swap) thay thế cho Lock, hay còn gọi là Lock-Free. Để thực hiện được lock-free thì ta cần sự hỗ trợ của hardware, thông qua các phép toán cơ bản (primitive) mà hardware hỗ trợ . Các phép toán đó gọi là các phép toán nguyên tử (Atomic operations) hay gọi là các thao tác “nguyên tử” duy nhất, tức là không thể chia nhỏ hơn được nữa.
Để dễ hiểu hơn về Atomic operation thì ta có thể liên tưởng tới việc bạn xem một bức hình, có rất nhiều các step để load bức hình đó lên như là đọc file vào bộ nhớ, giải nén hình ảnh, làm sáng các pixel trên màn hình, v.V … Và khi ta break các step nhỏ hơn và nhỏ hơn nữa thì ta sẽ tới một step mà không thể nhỏ hơn được nữa đó gọi là các chỉ dẫn máy (machine instruction) được điều khiển trực tiếp bằng phần cứng, và một vài machine instruction đó chúng được thực hiện trong một bước duy nhất, không thể cắt và không bị gián đoạn và ta gọi đó là các Atomic operations.
Compare and Set nghĩa là phép toán mà trước khi thay đổi một biến số nào đó thì CPU sẽ phải so sánh nó với giá trị trước khi hàm CAS được gọi, nếu giá trị khác nhau (đã bị thay đổi bởi một thread khác) thì sẽ không cho phép thực hiện phép thay đổi đó.
Cơ chế CAS sẽ thực hiện hai bước đơn giản là
- So sánh giá trị ta cần thay đổi với giá trị nguyên thủy (primitive) với giá trị ta sẽ thay đổi.
- Nếu phép so sánh trên khác nhau có nghĩa là đang có một thread nào đó đã thay đổi giá trị đó trước, ta sẽ không có phép việc thay đổi đó và thực hiện gán lại giá trị đã bị thay đổi trước (của một thread khác) cho giá trị đang cần thay đổi.
Trong Java, các class được bắt đầu bằng Atomic* ví dụ AtomicInteger là những class hỗ trợ cơ chế CAS, ví dụ ta hãy viết lại ví dụ tăng biến count đầu bài với vòng lặp 500 triệu lần
Single thread with CAS
Two thread with CAS
Khi chạy thử ta có kết quả như sau:
Tuy tốc độ có khá hơn chạy với cơ chế locking những tốc độ vẫn kém rất xa với chạy single thread.
2. Visibility of Change
Một main concept nữa của lập trình đa luồng đó là Visibility of Change nó có nghĩa là:
"Những thay đổi được thực hiện bởi một luồng (thread) với dữ liệu chia sẻ (share data), sẽ được thông báo và hiển thị (visible) ngay lập tức với các thread khác để duy trì tính nhất quán của dữ liệu (data consistency)" .
Visibility of change có thể đạt được nhờ với kỹ thuật rào chắn dữ liệu (memory barrier/fence).
Với CPU hiện đại bây giờ thì để tối ưu hiệu xuất nó sẽ bỏ qua việc sắp xếp trình tự thực thi.
Quay lại ví dụ tăng biến counter như ở đầu bài viết CPU sẽ tự do đưa ra các chỉ dẫn sắp xếp (reorder instructions) việc update đồng thời biến countervà "loop counter" một cách không có thứ tự. Tức là có thể biến counter đã được update bằng 1000 nhưng biến i (loop counter) thực tế trong thời điểm đó đã chạy tới 1002 hoặc chỉ mới tới 998.
Điều này cũng có thể xảy ra bởi lý do tính năng optimize code của compiler sẽ thay đổi thứ tự các dòng code một cách tự động để cải tiến performance ???
Ví dụ trên được thực hiện với single thread thì vấn đề trên không quan trọng lắm, vì kết quả sẽ luôn luôn đúng, nhưng khi chạy với nhiều thread thì việc này sẽ dẫn tới các kết quả rất khó lường.
Để dễ hiểu ta có thể hình dùng trường hợp trên giống như các lập trình viên làm việc trên các Source Control (Git, SVN ...), mỗi lập trình viên đại diện cho 1 Thread trên 1 CPU core, ví dụ ta có hai anh lập trình viên Nam và Nhân cùng làm việc trên 1 project và đang cùng update cùng lúc hai file là X và Y.
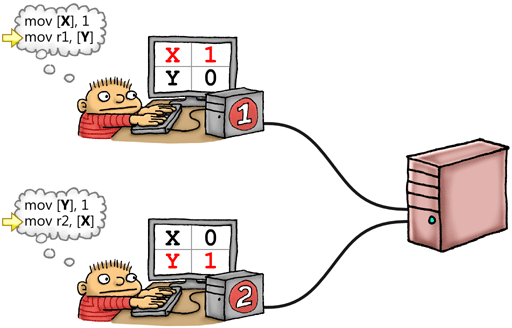
Cả hai cùng update trên hai bản sao của X và Y trên mỗi dữ liệu local của họ (L1, L2 cache) và mỗi thay đổi từ hai người đều không thể hiện (visible) cho bên kia thấy ngay lập tức mà phải đợi họ đẩy (push) dữ liệu
Memory barriers sinh ra để hạn chế việc này, nó là một "rào chắn dữ liệu" để bắt buộc CPU hay Compiler phải thực thi theo tuần tự mà lập trình viên đã đặt ra, và sau đây các mục tiêu chính của Memory barriers:
- Đảm bảo tất cả các chị dẫn thực thi của CPU phải theo đúng thứ tự trên tất cả CPU core đang thực thi trên cùng một share data, bằng cách đưa ra các hướng dẫn từ các barriers.
- Đảm bảo share data được cùng hiển thị trên tất cả các thread bằng việc đẩy nó vào các bộ nhớ share giữa các CPU (L3 cache || main memory) để tránh các trường hợp cache miss.
Và ta có 3 loại Memory Barrier chính là:
- Write Barrier: Là rào chắn được đảo bảo rằng CPU sẽ thực hiện tất các lần đọc dữ liệu được yêu cầu trước barrier trước khi nó thực hiện lần đọc sau barrier
- Read Barrier: Là rào chắn được đảo bảo rằng CPU sẽ thực hiện tất các lần ghi dữ liệu được yêu cầu trước barrier trước khi nó thực hiện lần ghi sau barrier
- Full Barrier: Là sự kết hợp của store và load barrier.
Memory Barrier trong Java được ứng dụng trong biến volatile, một biến volatile sẽ có một chỉ dẫn “write barrier” trước khi ta tiến hành ghi dữ liệu vào nó, và sẽ có chỉ dẫn “read barrier” trước khi ta tiến hành đọc dữ liệu từ biến đó, mục đích để đảm bảo rằng trong toàn bộ chương trình chúng ta chỉ thấy một giá trị nhất quán (consistent view) trên tất cả các thread. Ngoài các chỉ dẫn barrier thì các biến volatile luôn luôn được lưu tại Main Memory, do đó nó luôn luôn hiển thị (visible) ngay lập tức với các thread.
Ngoài ra Java cũng có một từ khóa final sử dụng “write barrier” để đảm bảo giá trị sau từ khóa final chỉ được có 1 giá trị duy nhất và không được phép thay đổi.
Trong Java ta có thể đặt các Memory Barrier bằng cách sử dụng gói sun.misc.Unsafe (mặc dù đây là cách không được khuyến khích sử dụng). Ví dụ ta sẽ sửa lại ví dụ tăng biến sharedCounter sử dụng multi-thread bằng cách đặt “read barrier” trước khi chương trình được truy cập vào biến sharedCounter:
Chạy thử với MAX bằng 1 triệu, kết quả kết quả sẽ như sau:
-- Chạy multi-thread khi chưa có "read barriers"
counter=522388
counter=733903
counter=532331
-- Và khi đã có "read barriers"
counter=999890
counter=999868
counter=999770Sau khi có áp dụng “Memory Barrier” bằng cách dùng gói thư viện sun.misc.Unsafe kết quả gần đạt được như ta mong muốn, nhưng kết quả vẫn chưa chính xác và thực tế là “Memory Barrier” vẫn chưa đủ để giải quyết bài toán “race condition” với cách không sử dụng Atomic.
Tóm lại với hiểu biết về Visible of Change và Mutual Exclusion thì thực tế là Concurrency is Hard and Locks are Bad, muốn lập trình đa luồng tốt thì cơ chế Lock-free với CAS và Memory Barrier là điều bắt buộc phải làm để đảm bảo rằng dữ liệu dùng chung (share data) luôn nhất quán (consistency).
Những vấn đề của hàng đợi — Queues
Mô hình Message-Queue hay được sử dụng để giải quyết vấn đề về Producer–Consumer và cũng có thể áp dụng trong trường hợp share memory giữa các thread mà ta gọi là sharing memory by communicating.
Ý tưởng rất đơn giản là ta sẽ có một layer đứng giữa trung gian cho việc liên lạc (communications) giữa các thread, và trong Java tao có giải pháp là sử dụng BlockingQueue ví dụ như hai implement của nó là LinkedBlockingQueue và ArrayBlockingQueue
Nghe tới Blocking là thấy Locking rồi mà đã locking là sẽ không có Lock-Free và không có thỏa mãn hai khái niệm về concurrency như nêu trên là mutual exclusion và visibility of change. Nhưng mà hãy từ từ thử phân tích một chút về hàm put trong class ArrayBlockingQueue coi:
Ta có thể thấy hàm put của ArrayBlockingQueue luôn sử dụng ReentrantLock để locking và chỉ cho phép trong một thời điểm cho có 1 element được add vào Queue và gửi một tín hiệu (signal) tới một thread đang rảnh rỗi bắt nó làm việc đi đang có dữ liệu kìa, điều này sẽ dẫn tới vấn đề về context switch trong Kernel.
Việc điều phối các process sẽ bao gồm, việc ngừng process hiện tại lại, lưu lại trạng thái của process này, lựa chọn process tiếp theo sẽ được chạy, load trạng thái của process tiếp theo đó lên, rồi chạy tiếp process tiếp theo. Quá trình này được gọi là Context Switch. Context Switch đôi khi phải phụ thuộc vào phần cứng (ví dụ việc lưu trữ lại trạng thái các thanh ghi mà process đang thực hiện). Context Switch là công việc tốn thời gian (trong bản thân kernel).
Và có một sự thật rất thú vị khác rằng, trong thực tế thì khi Queue đang hoạt động thì trạng thái của Queue hoặc là gần đầy hoặc là gần rỗng, điều này sảy ra vì sự khác nhau về tốc độ gửi nhận của Producer và Consumer. Nếu trường hợp Queue bị gần đầy thì chương trình sẽ bị sảy ra các tình huống tranh chấp hoặc bị locking của các Producer dẫn tới có thể các cached data hoặc các chỉ dẫn (instructions) bị mất như đã đề cập bên trên, dẫn tới hệ quả về performance của chương trình.
Một vấn đề nữa với Traditional Queues là nó sẽ lưu trữ dự liệu theo kiểu vào trước ra sau (FIFO), do đó Producer sẽ luôn đẩy dữ liệu vào đầu queue và Consumer sẽ luôn lấy dữ liệu từ cuối queue. Vấn đề là khi queue trong trạng thái gần rỗng thì rất có thể dữ liệu ở đầu, cuối và queue-size có thể ở cùng cache line dẫn tới vấn đề về false sharing như đã đề cập bên trên.
LMAX Disruptor
Những kỹ sư của LMAX Trading đã tạo ra một bộ thư viện có tên là LMAX Disruptor từ những hiểu biết rất sâu sắc về Mechanical Sympathy. Disruptor được tạo ra để hướng tới là một bộ thư viện về concurrency giúp chương trình có thể handle được một lượng khổng lồ các transaction với độ trễ cực thấp (low-latency), chi phí tài nguyên nhỏ và với cách sử dụng đơn giản (easy to implement).

Disruptor đã giải quyết rất tốt các vấn đề về concurrency như Mutual Exclusion với Look-free và Visibility of Change với Memory Barrier và các vấn đề với Queue với cấu trúc dữ liệu Ring-Buffer. Hãy cùng nhau tìm hiểu kỹ thêm về bộ thư viện này nhé.
Đầu tiên Disruptor sử dụng cấu trúc dữ liệu Ring-Buffer. Ring-Buffer là một mảng (array) vòng, kèm theo hai con trỏ pRead (consumer) và pWrite (producer)
Mỗi khi nhận lệnh ghi từ Producer, con trỏ pWrite sẽ ghi data vào ring-buffer, sau đó sẽ tăng lên 1 đơn vị pWrite++.
Mỗi khi nhận lệnh đọc từ Consumer, cỏn trỏ pRead sẽ tăng lên một. Sau đó đọc giá trị từ ring-buffer ra.
Khi 1 con trỏ tới được cuối mảng, nó sẽ cuộn lại vị trí đầu tiên. Đó là lý do vì sao ring-buffer còn được goi là circular-buffer (bộ đệm vòng)
Nếu (pRead+1) == pWrite, chứng tỏ bộ đệm đang trống, không có gì để đọc.
Nếu pWrite == pRead, chứng tỏ bộ đệm đang đầy. không thể ghi thêm.
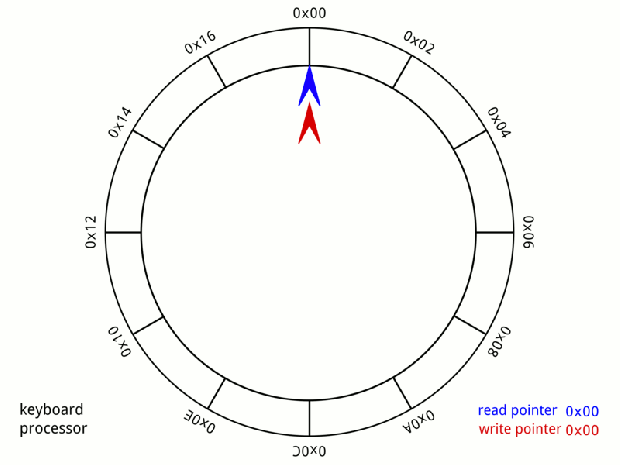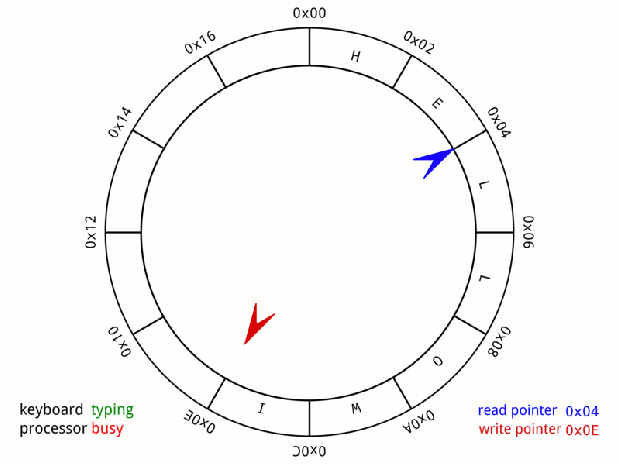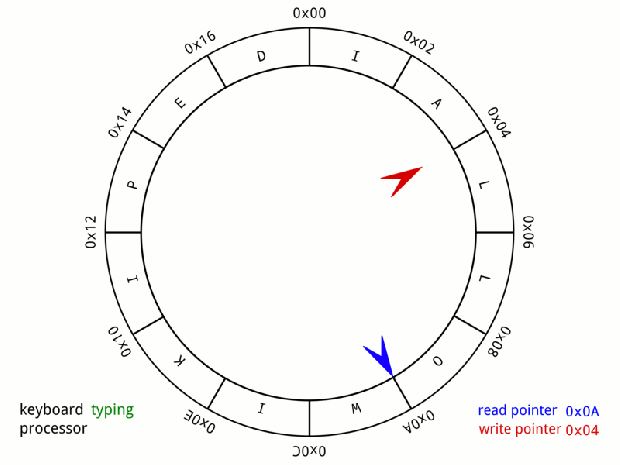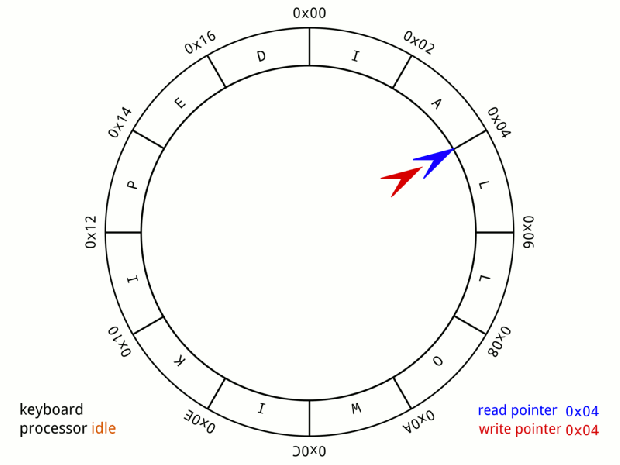
Chính nhờ sử dụng ring-buffer mà Producer có thể ghi dữ liệu trước vào vùng nhớ đệm (pre-allocate memory for events), nhờ việc đó mà giúp tránh được vấn đề về lock và contention bởi vì ở cấp độ hard-ware thì entries có thể được nạp trước (pre-load) và ring nhờ thế CPU process không cần phải quay lại main memory (L3 hoặc Ram) để lấy tiếp các item trong ring. Và các event có thể được sử dụng lại (object reuse) trong suốt thời gian Disruptor đang được hoạt động và tránh các rắc rối với garbage collector.
Từ phiên bản 3.0 thì Ring-Buffer không còn trở thành core-function của Disruptor và nó chỉ còn nơi chứa dữ liệu (events), các tương tác đến Ring sẽ qua các layers trung gian là Squencer và DataProvier. Các Producer sẽ tương tác với Sequencer (publish, next) và Consumer sẽ tương tác với DataProvider (get).
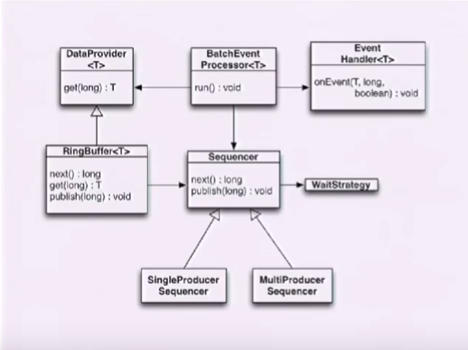
OK giới thiệu qua qua thế là đủ, giờ ta hãy bắt tay vào thiết kế một ứng dụng Disruptor đơn giản.
Với Maven:
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.2</version>
</dependency>Với Gradle
compile group: 'com.lmax', name: 'disruptor', version: '3.4.2'Version mới nhất có thể tìm thấy ở đây
Tạo một Event để chứa đựng các dữ liệu
Lớp EventFactory giúp Disruptor có thể chủ động pre-allocate các event vào Ring-Buffer.
Tạo một Consumer để lấy các dữ liệu từ Ring-Buffer về, ở Disruptor để làm điều này ta sử dụng bằng lớpEventHandler bằng các implement lại nó và Override hàm onEvent().
Ví dụ trên ta chỉ đơn giản là print ra log giá trị (value) của event và số sequence của Ring-Buffer, ta có thể hiểu với CTDL Ring-Buffer thì sequence chính là vị trí hiện tại của con trỏ pRead
Để có thể tạo một Ring-Buffer ta phải khởi tạo một Disruptor trước
Với hàm khởi tạo của Disruptor ta có những tham số sau:
- Event Factory — Chịu trách nhiệm tạo các object sẽ được lưu trữ tạo Ring-Buffer trong quá trình khởi tạo.
- The size of Ring Buffer — Kích thước của ring-buffer
- Thread Factory — Là sử dụng
ThreadFactoryđể khởi tạo các thread cho các bộ sử lý (processors) cho các event. - Producer Type — Chỉ định việc Disruptor làm việc trên một (single) hoặc nhiều (multiple) Producer bằng cách truyền tham số
Producer.SINGLEhoặcProducer.MULTI - Waiting strategy — Để định nghĩa các chiến thuật (strategy) chờ đợi để sử lý (handle) các vấn đề chênh lệch tốc độ gửi và nhận của Producer và Consumer hay còn gọi là "Producer and Consumer problem".
Giờ ta đã có một Disruptor giờ ta sẽ chỉ định Consumer nào sẽ được lắng nghe từ Disruptor bằng cách sử dụng hàm handleEventsWith()
Ta có thể có nhiều Consumer (multicast - parallel consumer) bằng cách khởi tạo một mảng các Consumer, nhưng ví dụ trên ta chỉ có một Consumer.
Để bắt đầu start một Disruptor ta hãy sử dụng hàm start ta sẽ có một Ring-Buffer được trả lại
Producer được thêm vào Ring-Buffer theo một trình tự dựa vào các sequence của Ring-Buffer và Producer chỉ luôn thêm dữ liệu và những slot đang rảnh (available) để tránh trường hợp ghi đè và những dữ liệu (overwrite data) chưa được Consumer lấy đi.
Để implement ta sử dụng Ring-Buffer để lấy ra sequence tiếp theo bằng cách hỏi Ring-Buffer đâu là sequence tiếp theo đang available bằng cách dùng hàm ringBuffer.next() , với trường hợp chỉ có một Producer (ProducerType.SINGLE) thì ringBuffer.next()hoàn toàn là lock-free bởi vì lúc này Disruptor chỉ sử dụng 1 thread duy nhất, còn nếu có nhiều hơn một Producer (ProducerType.MULTI) thì Disruptor sẽ sử dụng cơ chế CAS để giải quyết bài toán lock-free. Và các sequence luôn được tính toán hợp lý để event được add vào bên trái hoặc bên phải của Ring-Buffer để đảm bảo dữ liệu không nằm trên cùng một Cache-Line để tránh các tình huống về False Sharing có thể sảy ra.
Ngoài ra Disruptor sử dụng các SequenceBarrier để tạo ra các Memory Barrier để giúp cho việc các Consumer và Producer có thể đọc vào ghi dữ liệu một cách an toàn và có thứ tự (reading/writing safely) để thỏa mãn concept Visibility of Change trong lập trình đa luồng, tôi sẽ đề cập tới nó trong bài viết tới
Có lẽ bài viết nên kết thúc ở đây và để tìm hiểu sâu hơn về LMAX Disruptor tôi sẽ đề cập tới trong bài viết tiếp theo.
Đây là chủ đề khá khó để diễn đạt, người viết sẽ rất cảm kích nếu bạn đọc để lại comment nhận xét, bình luận và thảo luận thêm ở bên dưới nhé.
Link tham khảo:
